.svg)
AI-first transformation of talent and multidimensional data

September 5, 2023

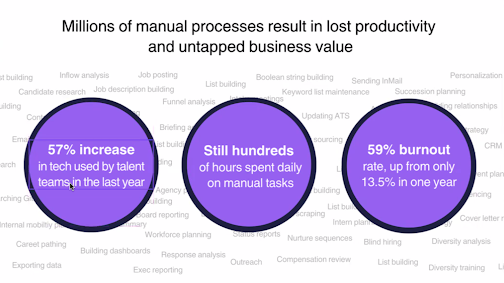
AI is a disruptive force to every aspect of our lives because it radically simplifies access to data for decision making. It will transform the way we work. McKinsey estimated that 21.5% of hours worked in the US economy would be automated by 2030 and increased the estimate to 29.5% with generative AI.
In the world of talent, AI might be used to automatically schedule and write questions for interviews, saving time for everyone. It could also tell you “your talent team is not going to make their headcount number this quarter,” providing meaningful feedback to help you adjust your course in the present to prepare for a future state. Analysis that previously required countless hours, data tools, and expertise can now be accessed in a matter of seconds.
At Findem, we believe that deep integration of AI will transform the role of talent within organizations, and we are building the talent data cloud and the platform to enable it. First, we will see efficiency gains as existing workflows can be partially automated with confidence and trust. Next, early adopters of our platform will begin to realize the value of automation via AI. Finally, this combination of efficiency and value will drive innovation and transformation, leading to business success in a fast changing world.
In this blog, we would like to share with you how Findem is building a talent data cloud architecture in the most responsible, ethical way to enable AI-first transformation as described by Wing Venture Capital with a focus on talent organizations. We are a group of big data, machine learning and product experts who are partnering with some of today’s most innovative companies and their talent leaders. Together, we look forward to a future that is data driven, human centered, and fair.
Understanding the limitations of public LLMs for talent
Large language models (LLMs) have been around for many years. But ChatGPT became wildly popular because it simply worked for the average user across what seems to be infinite use cases. On top of that, OpenAI released it with a set of APIs to encourage innovation. Companies like Findem have been able to rapidly develop middleware solutions for specific verticals and workflows across a broad range of industries. But these models all have their limitations. Let’s examine some of the limitations of generalized AI tools for use by talent teams and why the use of well thought through middleware layers will be critical for the AI-first transformation of talent.
Personally Identifying Information (PII) and Privacy
As companies incorporate GenAI-based tools, they must evaluate how PII is handled to maintain compliance and privacy while providing a meaningful result.
For example, let’s review a search for “give me a list of senior Java developers in the bay area with startup experience.” ChatGPT limits PII and so the response is: “Sorry, I cannot provide a list of specific people or directly connect you…” followed by sourcing strategies. The same search on Google Bard results in a list of a few people without context for why they were selected or how well they match the intention of the request. An appropriate talent solution will have to have a strategy for protecting PII and delivering results with a high level of confidence and relevant context to be useful.
Context for interpreting requests
Another architectural consideration is how to provide context to the LLM. AI is as good as the underlying data hence engineering the appropriate context is key to create meaningful, generalizable, and tailored experiences for the end users. But to process input efficiently, there is a limit to how much data can be provided to the LLM through the input window. Once the limit is reached, the model will eliminate content from the beginning of the input, which will remove the earlier context. Similarly, there is a great amount of calibration and fine-tuning required to map out where the LLM is allowed to get creative vs having interpreting prompts more strictly.
This is why Findem developed our own middleware to handle tasks across a range of use cases and workflows. We use vectorization in semantic search to identify which context and data to share with the LLM, given the limited context window LLMs have. Different parts of the workflow have context specific mappings.
For instance, Findem’s AI assistant for talent search provides the context and PII anonymization for this prompt: “give me a list of senior java developers in the bay area with startup experience” and can serve up the relevant candidates.

On each candidate profile, the embedded AI assistant provides more detail about that individual candidate and how they match the search criteria.

Within Findem analytics dashboards, the AI assistant is fine tuned to explain analytics and so on.
Hallucinations and trust
The AI is precise and authoritative in its generated answer. But there is a risk of hallucination where the AI makes assumptions that may or may not be true. Where there is a lack of data, AI will invent information. This is sometimes called a hallucination, and it is particularly concerning when it comes to decisions about people.
Simplistic data or data that is wrong or biased will throw off the model. The only way to have confidence in the AI is to have a depth and breadth of data you can trust to train the model. And even that approach can go wrong because the data that is needed to make the decision may not be the data on which the AI was trained originally.
Instead of offloading decision making to a trained platform, a carefully curated middleware should be used to ensure the right intent with the right set of data.
Building a better search with multidimensional data
Findem has built a foundational BI platform to represent people in 3 dimensions: person and company data over time. This 3D data schema is able to represent a person by converting any resume into a massively enriched profile, making entire careers searchable on command through a GenAI interface. This BI first, AI assisted approach eliminates assumptions and uncertainties, presenting an individual’s career in a factual and clear manner.
.png)
Findem dynamically and continuously leverages a language model to generate unique talent data from hundreds of thousands of sources. More than 1 trillion person and company data points are time ordered and become more than 1 million attributes to form the data layer of Findem’s Talent Data Cloud. This data lake contains new talent data in the form of attributes for every person, team, and company. These are the skills, experiences, and characteristics on which talent decisions are really based. The data lake is continuously refreshed from data sources. The data is factual. It is based on combining known facts to create a new fact.
Findem as a company, strictly adheres to all regional privacy regulations. We source data only from publicly available datasets. If a candidate decides to set any portion of their data to private, this change will be updated in the Findem system. Moreover, individuals can review and remove their information in accordance with our privacy policy.
Understanding intent to deliver data-driven insights
This deterministic and attributes-based understanding of 3D profile data feeds our system of intelligence to make it accessible to decision makers. The intelligence layer of the Findem architecture makes this data accessible in 3 distinct ways:
- Attribute-based search uses natural language processing to understand the intent of a search, so a search for software engineer would include member technical staff, software developer, SWE, etc., as well.
- The business intelligence layer applies analytics on an amalgamation of internal and external data for deep understanding of competitive and company workforces.
- AI-based automations streamline workflows and simplify access so people can focus on making decisions, engaging talent, and bringing more value.
The Findem architecture intentionally separates the activities of interpreting intent and queries from the generation of data, which is verifiable and factual. By running queries on real, factual data with context, not generalized data, bias is reduced and can be corrected for through validation and calibration. Having the language model and intent separate from the service gives users in the middle the opportunity to confirm, reconfirm, and validate the results.
Bringing GenAI into the application layer
At the application layer, Findem gives talent leaders and hiring managers insights across talent acquisition and talent management workflows: talent sourcing, CRM, candidate rediscovery, talent analytics, and market intelligence.
With the release of ChatGPT 4, we recognized the potential for transforming the work of talent teams as far reaching and dramatic. Developing the potential responsibly and in cooperation with talent leaders is essential and that has been our approach.
We worked with customers, advisors, and internal teams to identify where to deploy GenAI in existing workflows. Our initial launch targeted 4 areas in the talent acquisition workflow that were ripe for simplification and could make the most use of our 3D data:
- Search Assistant: Build a search from a query such as: “Find all the python developers in the Bay Area who have seen a B2B company grown from Series C through IPO.”
- Candidate Research Assistant: Understand a candidate profile and compose a pitch to a hiring manager.
- Campaign Assistant: Create a multi-touch email campaign or a single, personalized outreach in a performant and inclusive way.
- Analytics Assistant: Democratize data by explaining charts in our analytics dashboard to a user.
Findem anonymizes data before sharing it with LLMs in a way that is safe and secure. A platform’s ability to use intent not just to scale and speed up creation, but to create something more relevant and useful will become its core differentiator.
Next: automating business processes
The next wave of modern talent platforms will evolve to automate anything that can be automated. AI-first autonomous apps will not be programmed or hardcoded, but will emerge with guidance and validation to support organizational optimization. They will respond to changes in the environment, while elevating the human role at a scale that would not otherwise be possible. Findem’s Talent Data Cloud has been architected with autonomous applications in mind.

The next wave of autonomous apps will power the talent lifecycle and become available from generative AI natural language prompts, eliminating as much friction from the talent process as possible.
Architecting for an AI-first transformation of talent
Generative AI is the biggest disruption to business since the internet. The next wave of technological and business innovation will rely on the architectures and applications that leverage LLMs for innovation and disruption.
Findem was founded on AI with a BI-first architecture. We believe in the power of LLMs and GenAI to unlock the potential of being data-driven across the people organization, and are at the forefront of the AI-first transformation of talent.
With the latest release of Findem’s Talent Data Cloud, we’ve brought the convenience and ease-of-use promised by AI to automate and improve workfows.
We will continue to embed AI into our workflows, continue to advance our 3D data layer, and work closely with innovation partners to identify the next wave of AI-first applications across the talent lifecycle.
To learn more, please download our white paper on Generative AI, Data, and the Future of Talent or request a demo.



%20Paikeday.avif)

